K-Nearest Neighbor
K Nearest Neighbors (or KNN) is a predictive modeling technique that uses the K nearest points for prediction. We can use KNN for Classification, Regression, or Probability Estimation.
Classification
We are looking at data measuring customer talk time vs. the number of texts.
We have two distinct classifications; a high usage group and a low usage group. When we then get a new customer, we can use KNN to classify that customer into either of the two classification groups by measuring the distance between the new customer and known customers. This example shows that two of the three closest customers to this new datapoint are in the High Usage group.

Class Probability Estimation
For the second example, we try and predict if a customer will respond to a marketing campaign or not. Two of the three nearest data points to that unknown target customer did respond to the campaign, so we can predict that customer will also respond with a probability of 2/3

Regression
Finally, we can use KNN for regression. In the final example, we try to predict the Age of a customer by calculating the mean of the ages of the nearest three other neighbors

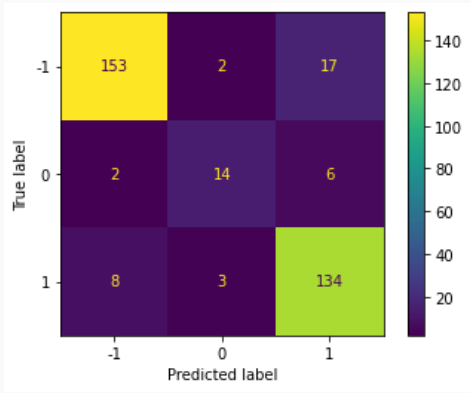
For this classification, will be using the PhishingData.csv dataset. The target variable here has three values. 1 means legitimate 0 is suspicious -1 is phishing
Start by importing the necessary libraries.

Import the data, create the models and create a confusion matrix